按硬件的不同特性进行分工,协同组成一个个人拥有的、具有公网连接能力的分布式计算/服务系统。
达到的目的是:
- 1 使用笔记本进行编辑和控制,但资源可分布在多个地址(个人住宅和办公场所)
- 2 各项服务的使用方便、稳定、安全
- 3 服务包含了:代码分发(Git)、文件传输(FTP)、网络服务(Web)、数据库服务(DB)、分布并行计算(CPU&GPU)、多媒体服务(听歌、看片、编辑)、消息服务(MQ)、一般通用服务(通过消息服务)
内容比较多,每部分的详细内容未来会嵌进网页链接。
1.1 服务的形式
Web、Git、FTP
MQ&&一般通用服务
1.2 机器的类型
主要负责存储,类似NAS
简单点的,类似dell的7070 1L主机。
高级点的,自己配置高级cpu+大内存。
配置了显卡的机器。
目前通过租用云主机,未来5g和ipv6应该可以使用家用网络混合。
1.3 搭建的方式
在ipv4的前提下,公网ip地址一定是不够用的,这里假定有1台公网ip主机(云主机)
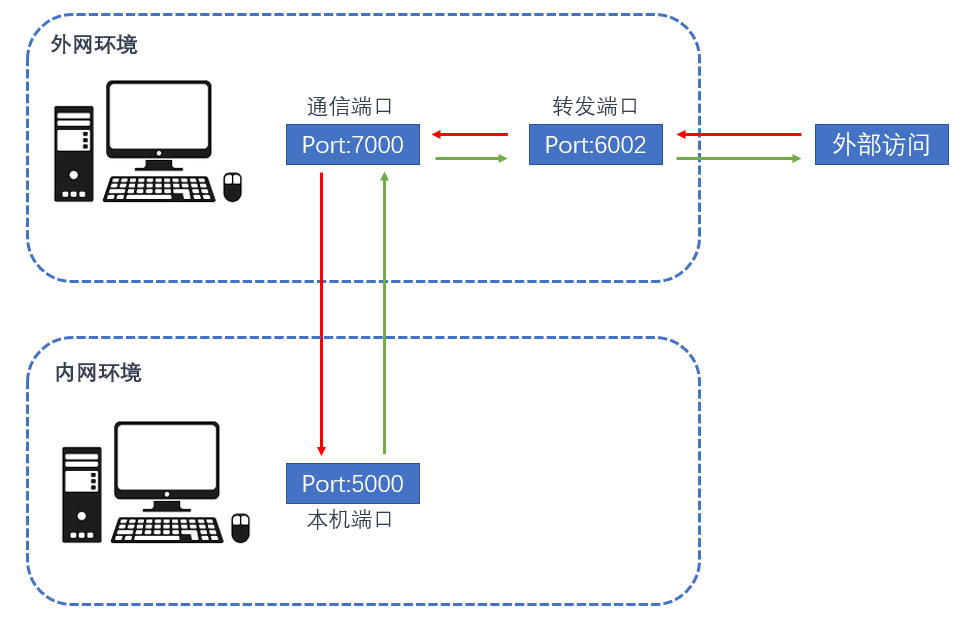
要实现互联,就要通过frp进行内网穿透,以及nginx反向代理来路由各个服务。可以理解这个过程有两个「流」:控制流和数据流。
frp最大的作用在于提供控制流。每个局域网机装了frpc,云主机装了frps, 配置好并启动服务后就实现了穿透。最主要的是ssh端口的转发,这样我们在个人终端(MAC)上只要有公网就可以控制局域网机拉取代码,启动服务等。这部分统称为控制流,可以单独设置,不一定需要docker-compose,也不一定需要用docker。
另外frp也可以指定需要提供转发服务的端口映射。这里假定存在需要直接访问某个主机的web服务,只要规划好端口端,然后在frps做好配置就可以了。nginx就负责向本机的端口进行路由。需要注意的是,如果局域网机只是通过消息通信进行服务提供的话,那么就不必做这个配置,而是在局域网机端管理好消息服务器的地址。
- 1 当前的机器(硬件资源)
Note: 从m4开始,机器的连接端口从6040,6041… 按顺序编号
硬件采购计划:
-
1、 2020双十一,采购3060Ti, 放到m1上,性能和能源比较平衡(m1 应该有4800左右cuda核心) ~¥3,000 | 增加张量计算能力
-
2、2021六一八,采购AMD CPU + N3090 的主机 。 ~ ¥18,000 | 3600U能力 + 5000cuda核心
- AMD 5950 ,16核32线程;
- Nvidia 3090
- 大内存,128G
- 主板还是要带wifi
- 至少一个1T的m.2固态,可能带一个6T机械(最好走pcie4)
- 水冷
-
3、2021下半年,Macbook pro 14寸(主要增加续航和内存)~ ¥18,000 | 续航和编辑
- 用ARM的CPU
- Mini LED屏幕
- 32G内存
-
显卡情况
着实没想到英伟达的显卡供应渠道这么混乱,本想着今年3060ti,明年3080的,现在想想还真没必要: -
1 供货的混乱反映了管理的混乱,这样一个公司不会是未来的主流的。现在的英伟达有点像当年的英特尔,凭借早期布局深度学习(cuDNN)打造了一个垄断的局面。看看现在的英特尔就知道未来的英伟达了。
-
2 技术的革新。从传统的技术上来看,苹果引领的arm潮流几乎是未来的主旋律了。从m1芯片上可以看出,arm结构是可以对神经网络进行特殊优化的,所以未来很可能出现arm基础的替代品:性能更强,功耗更低,体积更小。(这大概是前阵子英伟达急吼吼的要买arm的原因)
-
3 更大的变局。从制程工艺上,台积电比较领先,5nm,3nm ,但是很快就会走到1nm的一个极限,这个尺寸化学不可再分,物理可以,但这大概就要从宏观走入微观,没那么容易。而目前能看到的反而是,芯片何必是硅基?国内已经出了石墨烯,未来如何还真不好说。
接下来中科院将进一步研究如何将石墨烯晶圆这一物质实现碳基芯片的量产,一旦实现这个目标,中国就能在芯片领域获得全新的地位,从被动接受者摇身一变为规则制定者,硅基芯片在全球的垄断地位会被全面打破。
综上,没有必要过分追求英伟达所谓的高端,就着实际使用情况,按最低的够用标准去买就行(毕竟研究的时间很宝贵,能早点获得算力也是很重要的)
目前显卡的规划:
时间上并不着急,我觉得明年春节(2021.2)左右能买到1张3060ti就可以,也不用超频版,普通版就行,插在m5上面。3050ti(单独供电有点烦人)和3050应该会出单风扇版的,也可以买一张,价格估计不到2000,可以插在m4上。这样所有的台式机就都可以进行gpu计算了。
计划:
- 2021.2 之前买 3060ti
- 2021.618 买 3050ti/3050
再之后希望能有深度学习新的替代品可以用,毕竟我也不打游戏,不用光追什么的。
- arm gpu
- x86 tpu
- 石墨烯 gpu
- …
- 2 端口资源划分规则
对于公网机,规定三类端口的应用。 - 5xxx web服务
- 6xxx 消息通信或其他数据流服务
- 7xxx 控制流
另外,局域网机的的端口按10000 + 机器号*100 划分,预计不超过99台机器以及每台机器不超过100个应用。例如, 10000~10099属于公用的,暂不使用。10100 ~10199属于第一台机器的。以此类推。
目前端口占用情况
- 3 服务的估算
假设繁忙的服务会占掉1个逻辑cpu和4G物理内存,不太繁忙的应用大概是1/10,使用频度特别低或者cpu、内存消耗特别小的是1/100。所以反过来看,把机器表里可能运行的容器个数作为能力度量,服务的当前开销可以估计。
先把目前的资源都规划掉看看:
- 提供ip地址的路由解析 C <-> App Server
- 提供中间服务 C <- 公网机 -> App Server
- 公网机通过nginx组织服务
资源的录入按照局域网(网卡MAC)、主机(MAC)、cpu逻辑核数、内存大小、硬盘大小、通用计算力指数、GPU计算力指数。
- 局域网机直接和公网机互联(类似远程办公的员工主动向老板报告)
1.4 任务分发的方式
IO消耗:例如向服务器进行大量请求
算力消耗:是否是串行计算,是否是矩阵计算
存储消耗:集中or分布,结构化or非结构化
- 单次短时:简单的模型训练,计算
- 单次长时:负责的模型训练
- Forerver 短时:网络服务
- Forever 长时:强化学习
角色:
- 管理者(知所以然 TCP):应用级别的资源管理和调用, 发布work
- 调度者(知其然 TCP):任务级别的资源管理和调用,发布job
- 工作者(专注于事,不知其他)
- 1 通用工作者(CPU)
- 2 张量计算者(GPU)
配置:
外存/内存/cpu(GB/Core)
扩展:
局域网ID
全局分布or局域分布,是否并行
能效比(例如在吞吐量不大的时候使用cpu而不是gpu)
采用物理分布+冗余的方式以提供更好的稳定性
使用逻辑分布的方式(例如不同应用,不同客户的请求分开发往不同服务器)提供稳定性
原文链接:https://blog.csdn.net/yukai08008/article/details/108687003?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168605913416800225522928%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=168605913416800225522928&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~times_rank-10-108687003-null-null.268%5Ev1%5Ekoosearch&utm_term=%E7%BE%A4%E6%99%96nas%E5%AD%98%E5%82%A8%E3%80%81%E7%BE%A4%E6%99%96923%E3%80%81%E7%BE%A4%E6%99%96ipv6%E5%A4%96%E7%BD%91%E8%AE%BF%E9%97%AE%E3%80%81%E7%BE%A4%E6%99%96docker%E5%BF%85%E8%A3%85%E8%BD%AF%E4%BB%B6%E3%80%81%E7%BE%A4%E6%99%96%E7%9B%B4%E6%92%AD%E3%80%81%E7%BE%A4%E6%99%96+cpu%E3%80%81%E7%BE%A4%E6%99%96%E6%96%87%E4%BB%B6%E7%AE%A1%E7%90%86app%E3%80%81%E7%BE%A4%E6%99%96%E4%BD%BF%E7%94%A8%E8%AF%A6%E7%BB%86%E6%95%99%E7%A8%8B%E3%80%81%E7%BE%A4%E6%99%96quickconnect%E3%80%81%E7%BE%A4%E6%99%96%E7%B3%BB%E7%BB%9F%E4%B8%8B%E8%BD%BD%E3%80%81%E7%BE%A4%E6%99%96%E6%9C%8D%E5%8A%A1%E5%99%A8%E3%80%81%E7%BE%A4%E6%99%96nas%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B