Docke的基础配置多机训练
本文主要是根据个人配置Horovod Docker,并训练Partial-FC的经验完成这个教程。内容过长,但做到尽量的详细,还是希望帮助到大家吧。
第一步:安装nvidia版本的Docker。由于有些国外镜像需要pull很久。因此我们用一下阿里云的镜像库。
sudo touch /etc/docker/daemon.json sudo vim /etc/docker/daemon.json { "registry-mirrors":["https://alzgoonw.mirror.aliyuncs.com"] }sudo touch /etc/docker/daemon.json sudo vim /etc/docker/daemon.json { "registry-mirrors":["https://alzgoonw.mirror.aliyuncs.com"] }sudo touch /etc/docker/daemon.json sudo vim /etc/docker/daemon.json { "registry-mirrors":["https://alzgoonw.mirror.aliyuncs.com"] }
接下来,就可以直接安装了。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo service docker restartdistribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo service docker restartdistribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo service docker restart
测试nvidia-smi docker,直接run一个cuda镜像。
sudo docker run -it --rm --gpus all ubuntu nvidia-smisudo docker run -it --rm --gpus all ubuntu nvidia-smisudo docker run -it --rm --gpus all ubuntu nvidia-smi
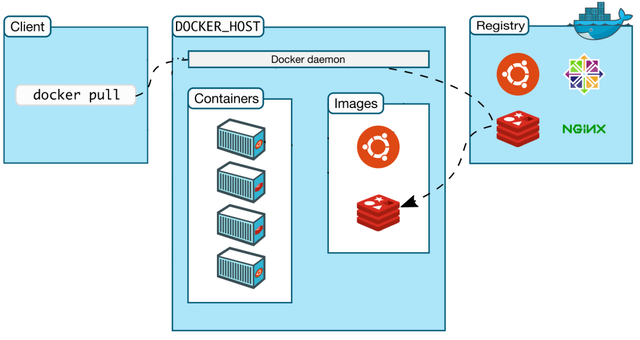
第二步:拉取Horovod的Docker官方版本。
docker pull horovod/horovod:0.19.3-tf2.1.0-torch-mxnet1.6.0-py3.6-gpudocker pull horovod/horovod:0.19.3-tf2.1.0-torch-mxnet1.6.0-py3.6-gpudocker pull horovod/horovod:0.19.3-tf2.1.0-torch-mxnet1.6.0-py3.6-gpu
如果需要其他版本的Horovod版本,可以自行查看。链接如下:
Horovod in Docker Hubhub.docker.com
第三步:运行该Docker。
注意,这一步很重要,涉及到很多重要参数配置。
sudo docker run -d -it -v /mnt/:/mnt/ -v /user/:/user/ -w /root --net=host --privileged --gpus 8 --shm-size=128g --name horovod horovod/horovod:0.19.3-tf2.1.0-torch-mxnet1.6.0-py3.6-gpusudo docker run -d -it -v /mnt/:/mnt/ -v /user/:/user/ -w /root --net=host --privileged --gpus 8 --shm-size=128g --name horovod horovod/horovod:0.19.3-tf2.1.0-torch-mxnet1.6.0-py3.6-gpusudo docker run -d -it -v /mnt/:/mnt/ -v /user/:/user/ -w /root --net=host --privileged --gpus 8 --shm-size=128g --name horovod horovod/horovod:0.19.3-tf2.1.0-torch-mxnet1.6.0-py3.6-gpu
这里解释一下几个参数:
-v /mnt:/mnt :就是将Dokcer内部的/mnt地址和Docker宿主机的/mnt映射上。在本人的工程中,这里放置了数据集。
-v /user:/user:这里同样的也是一个映射。在本人的工程中,这里放置了代码和用来存储训练完成的模型。
–shm-size=128g: 这里是Docker内部的分配的内存空间,大家尽量给大点,例如在Partial-FC中,大规模的人脸数据的缓存需要大量的内存空间,分配过小很可能跑不起来。
其他的参数就是常规的参数,按照贴的参数配置即可。
第四步:启动Horovod镜像。
首先查看该镜像的ID号,再进入即可。
docker ps docker exec -it b42d6498fa7e /bin/bashdocker ps docker exec -it b42d6498fa7e /bin/bashdocker ps docker exec -it b42d6498fa7e /bin/bash
这里的b42d6498fa7e是本人机器的ID号,需要改成自己的ID号。
第五步:运行例子
首先,进入官方给的examples文件中。
cd /examplescd /examplescd /examples
需要安装一下gluoncv。
pip install gluoncv -i https://mirrors.aliyun.com/pypi/simple/pip install gluoncv -i https://mirrors.aliyun.com/pypi/simple/pip install gluoncv -i https://mirrors.aliyun.com/pypi/simple/
然后修改几个参数。
Vim mxnet_imagenet_resnet50.pyVim mxnet_imagenet_resnet50.pyVim mxnet_imagenet_resnet50.py
batch_size改为8,log_iiteration 改为10。接下来就可以运行例子了。
horovodrun -np 4 -H localhost:4 python3 mxnet_imagenet_resnet50.pyhorovodrun -np 4 -H localhost:4 python3 mxnet_imagenet_resnet50.pyhorovodrun -np 4 -H localhost:4 python3 mxnet_imagenet_resnet50.py
运行结果如下:

第六步:运行Partial-FC训练代码。链接如下,这是支持多机超大规模的人脸数据集训练的高效框架。但如果需要运行其他的工程代码,可自行绕过这个步骤。
deepinsight/insightfacegithub.com

我们的基础实验参数为:
Dataset:facesemore. Batch_Size: 256. Backbone: R50. GPU:V100-8块.
config.rec_list = ['/mnt/faces_emore/train.rec',] config.head_name_list = ['emore'] config.num_classes_list = [85742] config.batch_size = 256 config.max_update = 180000config.rec_list = ['/mnt/faces_emore/train.rec',] config.head_name_list = ['emore'] config.num_classes_list = [85742] config.batch_size = 256 config.max_update = 180000config.rec_list = ['/mnt/faces_emore/train.rec',] config.head_name_list = ['emore'] config.num_classes_list = [85742] config.batch_size = 256 config.max_update = 180000
需要在Docker中安装额外Partial-FC工程需要的几个包:
pip install mxboard easydict -i https://mirrors.aliyun.com/pypi/simple/pip install mxboard easydict -i https://mirrors.aliyun.com/pypi/simple/pip install mxboard easydict -i https://mirrors.aliyun.com/pypi/simple/
然后,运行命令如下:
Docker=/usr/bin/python horovodrun -np 8 -H localhost:8 $Docker train_memory.pyDocker=/usr/bin/python horovodrun -np 8 -H localhost:8 $Docker train_memory.pyDocker=/usr/bin/python horovodrun -np 8 -H localhost:8 $Docker train_memory.py
运行结果如下图所示。

第七步:save Horovod Docker。
docker ps #查看id号 docker commit -a “user" -m “Horovod" b42d6498fa7e horovod:v1 docker images #可以查看当前的docker容器docker ps #查看id号 docker commit -a “user" -m “Horovod" b42d6498fa7e horovod:v1 docker images #可以查看当前的docker容器docker ps #查看id号 docker commit -a “user" -m “Horovod" b42d6498fa7e horovod:v1 docker images #可以查看当前的docker容器
b42d6498fa7e为本机上ID号。改为自己的即可。

保存Horovod Docker即可。
docker save -o horovod.tar horovod:v1docker save -o horovod.tar horovod:v1docker save -o horovod.tar horovod:v1
第八步:将horovod.tar传到另外一台机器,并进行如机器一一样的操作。
先load下来这个打包好的horovod.tar。
docker load --input horovod.tardocker load --input horovod.tardocker load --input horovod.tar

再运行该docker, 并进入。
docker run -d -it -v /mnt/:/mnt/ -v /user/:/user/ -w /root --net=host --privileged --gpus 8 --shm-size=128g --name horovod-1 horovod:v1 docker ps #获得id号 docker exec -it id /bin/bashdocker run -d -it -v /mnt/:/mnt/ -v /user/:/user/ -w /root --net=host --privileged --gpus 8 --shm-size=128g --name horovod-1 horovod:v1 docker ps #获得id号 docker exec -it id /bin/bashdocker run -d -it -v /mnt/:/mnt/ -v /user/:/user/ -w /root --net=host --privileged --gpus 8 --shm-size=128g --name horovod-1 horovod:v1 docker ps #获得id号 docker exec -it id /bin/bash
第九步:配置两者的ssh登陆服务。这里只展示一个机器的horovod Docker的ssh登陆服务配置,另外的机器的docker的ssh登陆服务配置相同。
1. 修改sshd配置
vim /etc/ssh/sshd_configvim /etc/ssh/sshd_configvim /etc/ssh/sshd_config
改动如下图所示:

2. 保存配置,启动sshd, 并查看ssh是否启动。
/usr/sbin/sshd # 启动命令 ps -ef | grep ssh # 查看是否启动/usr/sbin/sshd # 启动命令 ps -ef | grep ssh # 查看是否启动/usr/sbin/sshd # 启动命令 ps -ef | grep ssh # 查看是否启动

注意启动ssh的上下变化。
3. 设置密码。
passwdpasswdpasswd

一定要记住这个密码,后面配置无秘登陆需要这个密码。
4.测试一下宿主机是否可以登陆内部horovod Docker。
在10.0.9.9上宿主机上登陆root docker。

接下来,同样的配置方法再另外机器上配置ssh登陆服务即可。
第十步:配置无秘登陆。
1. 在A服务器上生成密钥。
ssh-keygen -t rsassh-keygen -t rsassh-keygen -t rsa

2. 在B服务器上创建.ssh文件夹
ssh -p 12345 root@Bssh_path mkdir -p .sshssh -p 12345 root@Bssh_path mkdir -p .sshssh -p 12345 root@Bssh_path mkdir -p .ssh
3. 将公钥添加到B服务器的authorized_keys里
cat .ssh/id_rsa.pub | ssh -p 12345 root@Bssh_path 'cat >> .ssh/authorized_keys'cat .ssh/id_rsa.pub | ssh -p 12345 root@Bssh_path 'cat >> .ssh/authorized_keys'cat .ssh/id_rsa.pub | ssh -p 12345 root@Bssh_path 'cat >> .ssh/authorized_keys'
4. 测试是否可以免密登陆
ssh -p 12345 root@Bssh_pathssh -p 12345 root@Bssh_pathssh -p 12345 root@Bssh_path

第十一步:两台机器运行Partial-FC.
到此基本的准备工作已经完成了。对于两台机器而言,将代码和存放模型地址放在/user底下。将数据集放在/mnt底下即可。对于这两个都是共享的两个地址即可。
直接上运行代码。
Docker=/usr/bin/python horovodrun -np 16 -H Assh:8, Bssh:8 -p 12345 $Docker train_memory.pyDocker=/usr/bin/python horovodrun -np 16 -H Assh:8, Bssh:8 -p 12345 $Docker train_memory.pyDocker=/usr/bin/python horovodrun -np 16 -H Assh:8, Bssh:8 -p 12345 $Docker train_memory.py
接下来如图所示的运行log。

如图,horovodrun共启动了16个训练进程。到此为止,整个多机的Horovod的多机Docker配置及运行就完成了。
另外,再安利一下目前开源的多机大规模人脸训练框架Partial-FC:deepinsight/insightface。
多谢大家的关注。
原文链接:https://blog.csdn.net/weixin_29075633/article/details/112104566